Modelos de Linguagem
Índice
Modelo Generativo
Escolha do modelo
Foram avaliados diferentes modelos de linguagem com o mesmo conjunto de parâmetros e prompt:
| Modelo | Resultado |
|---|---|
| Gemma 3 1B (escolhido) | - Extração de termos simples e compostos de forma concisa. - Omissão de habilidades pontuais corrigível via prompt ou schema. - Preenchimento da maioria dos campos, com classificação restrita ao campo soft skills. |
| Qwen 2.5 0.5B | - Preenchimento integral do JSON. - Inabilidade de capturar termos compostos. |
| Llama 3.2 1B | - Latência de inicialização elevada (40 a 60 segundos). - Não identificou knowledge skills. |
| Mistral 3 3B | - Extração correta de competências e categorias. - Inviabilidade devido ao tempo de execução. |
| Gemma 3 4B | - Extração correta de competências e categorias. - Inviabilidade devido ao tempo de execução. |
| Liquid 2 1.2B | - Extração restrita a termos simples. - Omissão dos campos position e company. |
Experimentos realizados:
Prompt
Você é um sistema de extração de informações estruturadas.
## TAREFA
Extraia APENAS as informações presentes no texto da vaga abaixo.
## REGRAS CRÍTICAS
- Extraia SOMENTE skills que estão EXPLICITAMENTE mencionadas no texto
- NÃO invente, infira ou suponha skills não escritas
- Se uma skill não aparecer no texto, NÃO a inclua
- Se position/company não identificáveis, use "Não informado"
- Classifique cada skill no tipo correto conforme as definições abaixo
## DEFINIÇÕES (Taxonomia ESCO SkillCompetenceType)
- Knowledge: Áreas de conhecimento teórico (ex: desenvolvimento web, marketing digital, gestão de projetos, administração de banco de dados)
- Hard Skills: Habilidades técnicas práticas e ferramentas específicas (ex: Python, Docker, Git, Excel, Figma)
- Soft Skills: Competências comportamentais e interpessoais (ex: comunicação, trabalho em equipe, proatividade, liderança)
## TEXTO DA VAGA
Titulo: {titulo}
Empresa: {empresa}
Requisitos: {requisitos}
Atividades: {atividades}
## SAÍDA
Retorne APENAS JSON válido, sem texto adicional.
Configuração da saída
{
"type": "object",
"properties": {
"position": {
"type": "string"
},
"company": {
"type": "string"
},
"hard_skills": {
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true,
"default": ["Não informado"]
},
"soft_skills": {
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true,
"default": ["Não informado"]
},
"knowledge_skills": {
"type": "array",
"items": {
"type": "string"
},
"minItems": 1,
"uniqueItems": true,
"default": ["Não informado"]
}
},
"required": [
"position",
"company",
"hard_skills",
"soft_skills",
"knowledge_skills"
]
}
Configuração do modelo
| Parâmetro | Definição | Valor | Racional |
|---|---|---|---|
| Temperatura | Valores entre 0 e 1, onde quanto mais perto de 1, mais variadas são as respostas(maior criatividade), enquanto mais perto de 0, as respostas são as mesmas (menor criatividade) | 0.0 | Evitar múltiplas saídas possíveis para uma entrada, caso seja reprocessada |
| CPU Threads | Quantidade de Threads de CPU utilizadas | 4 | Limitações Computacionais |
| Top K | O modelo escolherá tokens entre os K mais prováveis | 40 | Reduz também a criatividade. |
| Top P | O modelo escolherá tokens que, quando juntos, estão entre os P mais prováveis | 95% | Garantir assetividade |
| Min P | Tokens abaixo de Min P de probabilidade são descartados | 5% | Considerar vários tokens, só descartando os que são realmente |
| Repeat Penalty | A diferença para 1.0 representa, em percentual, em quanto as repetições de tokens serão reduzidas | 1.0 (0% de punição) | Não há problema em repetir tokens |
| Structured Output | Exige que a saída seja no formato JSON | Sim (Schema acima) | Necessário garantir que a saída completa seja JSON para consumo pelos serviços |
| Speculative Decoding | Um LLM pequeno gera os tokens, um bem maior valida, o que é mais rápido do que um maior fazer o processo inteiro (Veja Explicação IBM) | Não | Necessário ter dois modelos com uma quantidade muito diferente de parâmetros (ex: 3B e um de 70B) para melhores resultados |
Gemma 3 1B (Escolhido)
Resultado obtido:
{
"position": "Board Certified Behavior Analyst",
"company": "Community Options, Inc.",
"skills": [
{
"name": "Applied Behavior Analysis (ABA)",
"type": "knowledge"
},
{
"name": "Functional Behavioral Assessment (FBA)",
"type": "knowledge"
},
{
"name": "Positive Behavior Supports",
"type": "knowledge"
},
{
"name": "Data Collection",
"type": "knowledge"
}
]
}
Métricas e observações:
- 26.77 tokens/segundo;
- 198 tokens gerados;
- Tempo total: 4.01 segundos;
- Respeitou os tipos definidos pela ESCO;
- Executado via few-shot prompting sem fine-tuning adicional.
Qwen 2.5 0.5B
Problema identificado:
{
"skills": [
{
"name": "Positive Options utilizes trauma informed care...",
"type": "knowledge"
}
]
}
Métricas e observações:
- 35.81 tokens/segundo;
- Extração das frases completas ao invés da entidade específica.
Llama 3.2 1B
Resultado obtido:
{
"skills": [
{
"name": "Board Certified Behavior Analyst",
"type": "hard"
},
{
"name": "Applied Behavioral Analysis",
"type": "hard"
}
]
}
Métricas e observações:
- Inconsistência na rotulação das competências extraídas com base na definição da ESCO (ex.: classificar como
hard).
Mistral 3 3B
Métricas e observações:
- 608 tokens gerados;
- Tempo total de aproximadamente 20 segundos;
- Produziu verbosidade excessiva não requerida pelo serviço de roteamento.
Gemma 3 4B
Métricas e observações:
- Tempo total de aproximadamente 20 segundos;
- A acurácia atingida acompanhou degradação inaceitável para a fila de eventos do sistema.
Liquid 2 1.2B
Métricas e observações:
- Variação de latência entre 8 e 20 segundos;
- Omissão de atributos primários exigidos pelo validador.
Configurações
| Parâmetro | Valor | Racional |
|---|---|---|
temperature | 0.0 | Define a geração determinística para assegurar resultados idênticos a partir de entradas idênticas. |
top_k | 40 | Restringe a geração aos 40 tokens subsequentes mais prováveis. |
top_p | 0.95 | Estabelece um corte nos tokens cuja probabilidade acumulada exceda 95%. |
min_p | 0.05 | Remove tokens candidatos que possuam probabilidade de escolha individual inferior a 5%. |
repeat_penalty | 1.0 | Exclui penalizações algorítmicas por repetições, viabilizando o reuso de descritores de competência idênticos. |
num_ctx | 8192 | Define a alocação da janela de contexto para processar o prompt e o currículo e vaga. |
num_batch | 1024 | Ajusta o tamanho de bloco no carregamento para aumentar a taxa de transferência paralela do processador gráfico. |
Como foi usado
O modelo Gemma 3 1B é utilizado para realizar a extração de habilidades com base nos textos de currículos e descrições de vagas no serviço Skill Extractor.
Modelo de Embbeding
Escolha do modelo
O modelo embeddinggemma foi selecionado devido ao seu desempenho que superou a de modelos com mais parâmetros (ex: multilingual e bge-m3), além de sua integração nativa com o Ollama.
Benchmark comparativo com outros modelos:
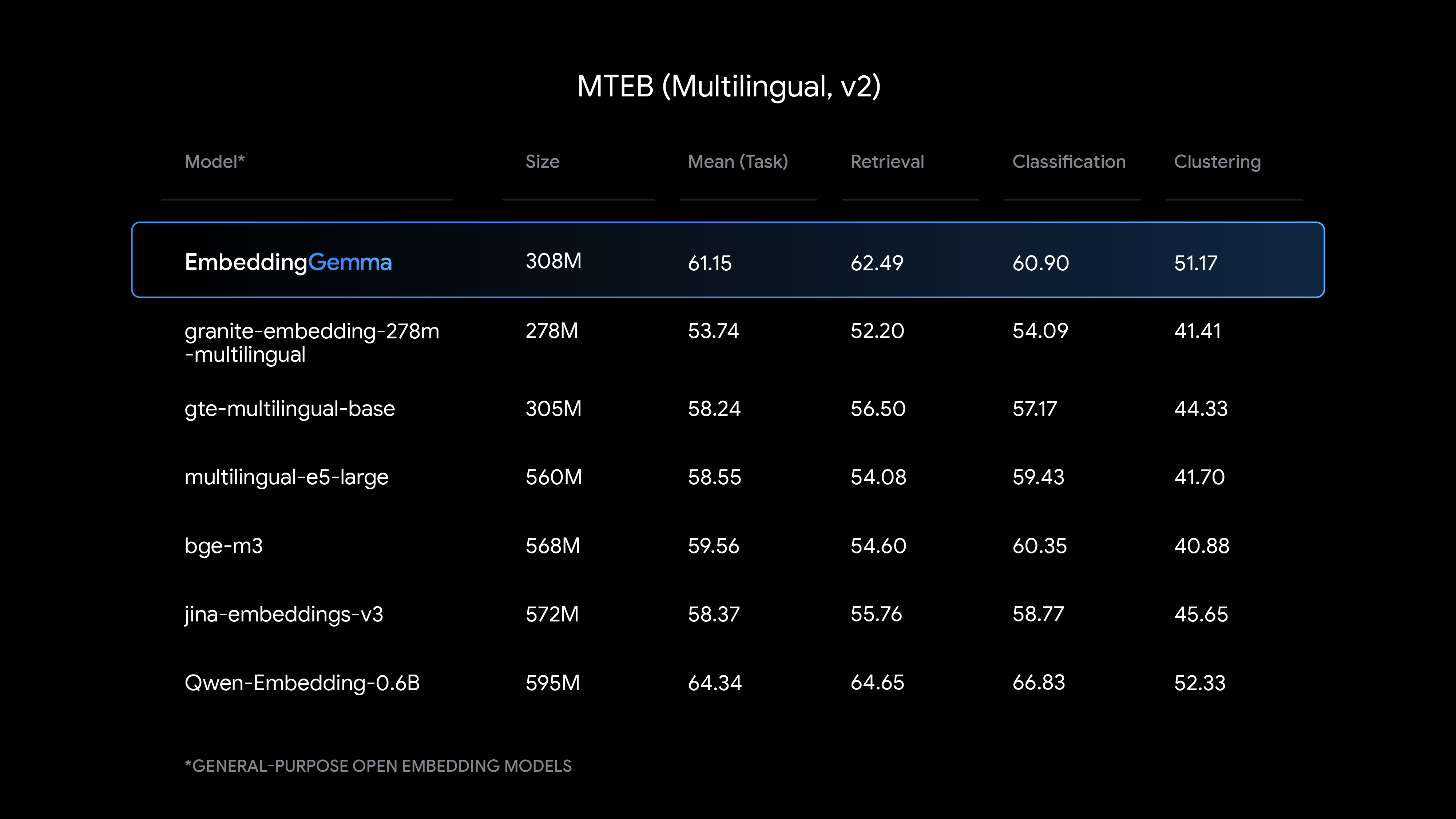
Fonte: Ollama/embeddinggemma
Configurações
O modelo opera com os parâmetros padrão do fornecedor, mantendo seu comportamento e número de dimensões.
Como foi usado
O modelo é utilizado para gerar embeddings vetoriais para os registros das competências da ESCO no serviço Loader ESCO. Já no serviço Entity Linker, ele é utilizado para a seleção dos candidatos mais similares das competências extraídas.
Ollama
O Ollama opera como o motor de inferência e API de servidor local. Sua instalação executa os arquivos e gerencia as alocações computacionais exigidas pelas requisições de serviço do projeto.
Configurações do Ollama
| Variável | Valor | Racional |
|---|---|---|
OLLAMA_FLASH_ATTENTION | 1 | Ativa a operação de Flash Attention (apenas para GPUs NVIDIA), reduzindo a ocupação de memória KV exigida pela inferência contínua. |
OLLAMA_MAX_LOADED_MODELS | 2 | Estabelece a persistência de 2 instâncias diferentes na VRAM, permitindo a manutenção simultânea dos modelos Gemma 3 1B e embeddinggemma. |
OLLAMA_KEEP_ALIVE | -1 | Remove a rotina de descarregamento por ociosidade. Os modelos alocados mantêm-se em VRAM permanentemente para evitar as penalidades de tempo de inicialização. |
OLLAMA_NUM_PARALLEL | 2 | Limita o enfileiramento da placa gráfica a 2 processos paralelos. |
Resultados e ganhos de latência p95 obtidos para cada conjunto de configuração, tomando como base de comparação o modelo gemma3:1b executado sob as configurações padrão do Ollama (baseline):
Configuração 1
- Flash Attention
- Carregamento persistente em memória (
OLLAMA_KEEP_ALIVE=-1) - Resultado: Redução de aproximadamente 8% na latência p95 em relação ao baseline.
Configuração 2
- Flash Attention
- Carregamento persistente em memória (
OLLAMA_KEEP_ALIVE=-1) num_batch=1024num_ctx=4096- Resultado: Redução de aproximadamente 50% na latência p95 em relação ao baseline.
Configuração 3
OLLAMA_NUM_PARALLEL=8- Resultado: Degradação do desempenho global em relação ao baseline e ocorrência de falhas por tempo limite excedido (timeout).
Configuração 4
num_batch=2048- Resultado: Tempo de resposta pior do que a baseline.
Como foi usado
O Ollama é utilizado para expor os modelos de linguagem para os serviços do projeto, com uma API REST unificada, abstraindo de gerenciar arquivos .gguf e a execução dos modelos.
ADR's Relacionadas
| ADR | Data | Decisão |
|---|---|---|
| ADR-018 | 2026 | Escolha do modelo Gemma 3 1B como o ideal para extração local de competências. |
| ADR-035 | 2026 | Uso do Neo4j Vector Index e do modelo embeddinggemma do Ollama para indexação e busca vetorial KNN. |
| ADR-041 | 2026 | Parametrização de performance do Ollama para otimizar a latência p95. |